
At the recent European Microsoft Fabric Community Conference, there were quite a few exciting announcements, including new capabilities that make it easier than ever to manage data within OneLake. With features like shortcuts and mirroring, Microsoft is steadily removing the friction that used to come with working across multiple data sources, formats, and clouds. Instead of relying on heavy ETL pipelines, duplicating datasets, or wrestling with synchronization headaches, organizations can now treat their entire data estate as if it lives in one place.
With each new integration, Microsoft has been knocking down the barriers that keep enterprises from achieving a unified data foundation. This trend continued with the announcement of the public preview for Mirroring for Google BigQuery in Microsoft Fabric, a milestone that carries major significance for organizations pursuing a multi-cloud strategy.
In this article, we'll take a closer look at this announcement and see what it potentially unlocks for customers who run workloads in both Google Cloud and Microsoft Azure.
Frictionless Data Access Across the Enterprise
With the introduction of Mirroring for Google BigQuery, Microsoft is showing how Fabric can deliver frictionless data access across the enterprise. In the past, we mostly had to rely on traditional ETL/ELT pipelines to move and reshape data before it could be analyzed. While those patterns are still fully supported in Fabric Data Factory, they’re no longer the only option.
By combining mirroring with OneLake shortcuts, Fabric gives you the flexibility to connect to data where it lives, unify it under a single governance model, and make it instantly available for reporting and advanced analytics. To see how this works, check out demo video below from Microsoft.
Streamlining Development with Power BI
One of the biggest advantages of mirroring BigQuery data into OneLake is how much simpler it makes building and maintaining reports in Power BI.
Traditionally, Power BI report developers faced a difficult tradeoff when it came to working with BigQuery data:
DirectQuery connections to BigQuery ensured that data was always current, but query performance wasn't usually very great.
Import mode delivered much better performance, but required scheduled refreshes that meant reports were never fully up-to-date.
With the new Direct Lake mode in Fabric, that tradeoff disappears. Mirrored BigQuery data lands in OneLake in a native format that Power BI can consume directly, giving developers the speed of Import mode with the freshness of DirectQuery. The result is a more frictionless experience:
Reports run faster, with fewer query bottlenecks.
Development cycles are streamlined, since refresh strategies and query tuning become less of a burden.
Users gain confidence that they’re always working with the most current information available.
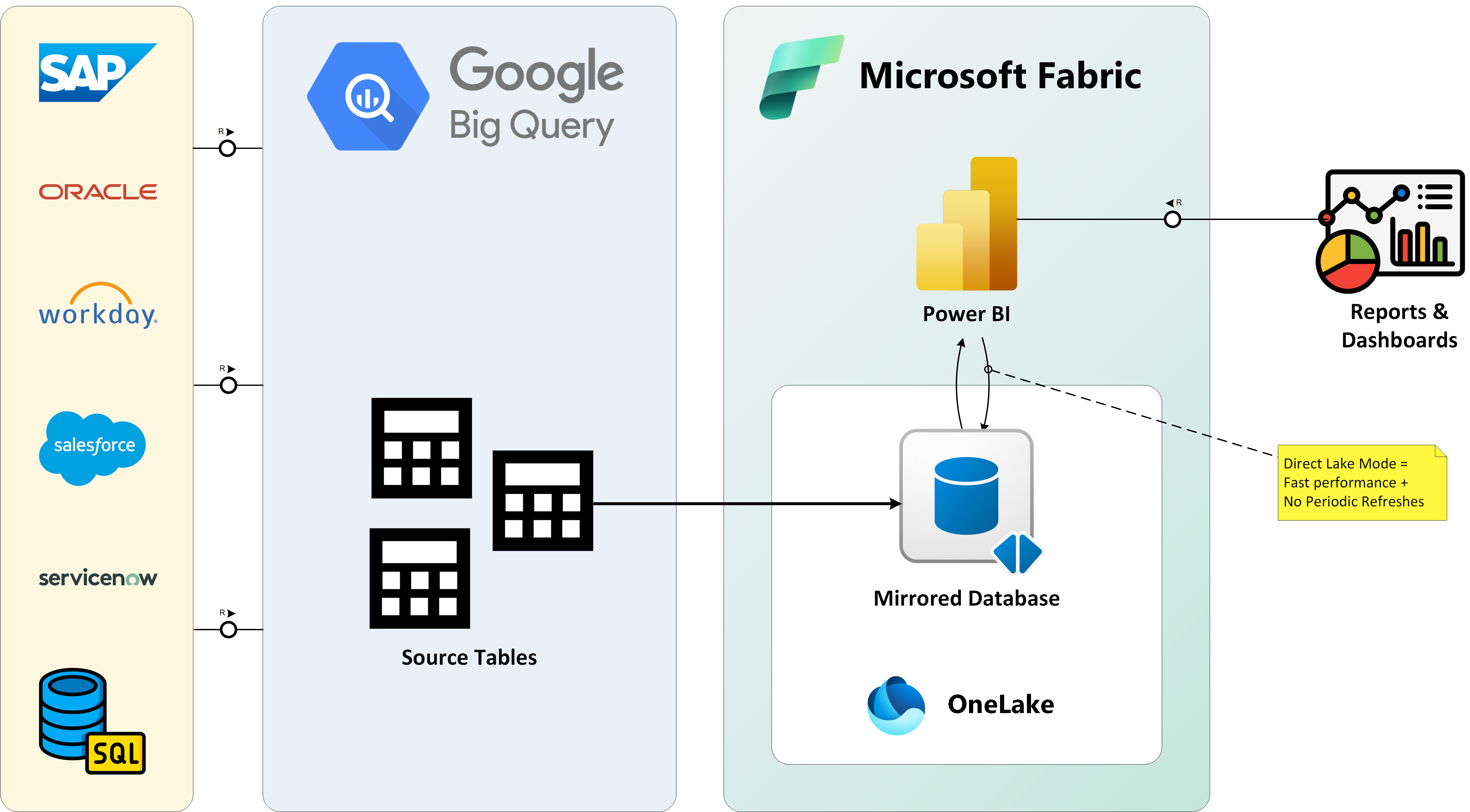
Figure 1: Streamlining Data Integration with Data Mirroring and Direct Lake Mode in Fabric
For teams building and iterating on BigQuery reports, this means less time spent on workarounds and performance optimizations and more time focusing on delivering insights that matter.
Closing Thoughts
The public preview of Mirroring for Google BigQuery in Microsoft Fabric represents more than just another connector, it’s a glimpse into the future of enterprise data management. By bringing BigQuery into OneLake alongside other mirrored sources and shortcut-linked data, Microsoft is reinforcing its vision of a unified, open data foundation where performance and freshness no longer have to be tradeoffs.
For organizations, the value is clear: less time spent moving and reshaping data, fewer compromises in reporting, and more confidence in the insights that drive decision-making. Whether you’re running a single cloud or a multi-cloud strategy, Fabric’s approach to seamless integration puts the focus back on turning data into actionable intelligence.